At CSUN 2017 I opened the conference on Wednesday morning with a presentation on audio description. The purpose of my presentation was to muse about how organizations with large quantities of videos might meet Success Criterion 1.2.5 of the W3C Web Content Accessibility Guidelines (WCAG) 2.0:
1.2.5 Audio Description (Prerecorded): Audio description provided for all prerecorded video content in synchronized media. (Level AA)
The purpose of audio description is to ensure that visual content is accessible to people who can’t see it. In some cases the information is sufficiently communicated via the program audio. However, when that isn’t the case, a supplemental audio track must be provided that includes brief description of the visual content.
The WCAG 2.0 accompanying recommendations for How To Meet SC 1.2.5 includes several “Sufficient Techniques” for accomplishing this, all of which focus on providing a second, user-selectable, audio track or movie that has human-narrated audio descriptions mixed in.
The recommendations also include an “Advisory Technique”, Using the track element to provide audio descriptions. This is the technique supported within HTML5, using the <track> element with kind=”descriptions” (more on this below). This is presumably an “Advisory Technique” because it isn’t well supported yet by media players. However, I’m convinced that this technique has merit and is more scalable than any of the “Sufficient Techniques” for describing tens of thousands of videos, which is the scale of the problem at most universities.
In my presentation at CSUN, and in this follow-up blog post, I took a closer look at the two methods.
Method One: Alternative audio track, human-narrated
The American Council of the Blind’s Audio Description Project lists over 60 audio description service providers. Many of these providers offer live description for local performances, not necessarily description of recorded video. In exploring the options for the University of Washington, I narrowed the list to 18 providers who seemed to provide the types of services we need, and sent them all an email inquiry with questions about their standard deliverables, prices, and turnaround times.
Ten of the 18 providers who I contacted with questions replied with answers. The most common response to all questions was: It depends.
Description ain’t captioning. With captioning, there are a handful of vendors that have negotiated contracts with large organizations and deliver captioning services on demand through APIs with YouTube, lecture capture systems, video asset management systems, etc. Prices vary depending on the required turnaround time, but otherwise are fixed within the contract. We know exactly how much captions will cost for a given video, and the process is extremely simple, and in some cases automatic.
In contrast, most audio description service providers don’t provide a fixed rate because the needs for description vary so widely per video. Some videos have no spoken audio at all and require extensive description; some videos only have a few brief moments where description is needed; some videos have very little silent time in which to inject description, therefore careful choices and efficient language are paramount (which involves time and skill).
Here’s a summary of the responses I received from the ten audio description service providers:
- Five providers (50%) couldn’t provide me with a standard pricing model. They prepare quotes on a per-video or per-project basis. Those who were willing to provide an estimate of their standard pricing ranged from $12 per video minute to $75 per video minute.
- Five of the providers (50%) expressed their typical turnaround time in days. Two others expressed theirs in weeks (“4-6 weeks” and “6 weeks”). The remaining three said “it depends”.
- All but one of the providers expressed a willingness to negotiate on pricing, and all expressed some flexibility and willingness to collaborate with clients to ensure clients’ unique needs are met.
In my CSUN presentation, I shared an example video from the University of Washington: The Best Of UW 2016 video released by the President’s office as a year-ending celebration of theUW’s many accomplishments in 2016. I kicked off my session by inviting the audience to close their eyes for two minutes while we watched the video together. That was an eye-opening experience for many attendees (they told me so afterwards). The video is packed with accomplishments that truly makes me proud to be a Husky. But all of this is communicated visually—there’s no spoken audio at all. Therefore, to people who can’t see it, there were no accomplishments at the UW. There is only music.
This video was unveiled to the UW community as an embedded YouTube video on the President’s blog. Immediately beneath the video, there’s a paragraph that says “Video is also available with audio description”. The phrase “audio description” links to the described version of the video on YouTube. The described version was professionally scripted and narrated by one of the ten vendors, Audio Eyes. This is do-able for the occasional high profile videos such as those released by the President’s office, as well as videos needed for providing individual accommodations to students, but we have tens of thousands of videos. Given the high cost of outsourcing description, and the need for most description providers to bid on individual videos or projects, I can’t see this method on its own being viable or sustainable for our meeting WCAG 2.0 Level AA.
Method #2: Text-based Audio Description
HTML5 introduced the <video> element, and with it introduced the <track> element. The <track> element allows authors to specify timed text tracks to be synchronized with a video. There are five kinds of tracks, identified by the kind attribute: captions, subtitles, descriptions, chapters, and metadata.
For all of these kinds of tracks, the <track> element references a plain text file in Web Video Text Tracks (WebVTT) format.
Imagine a video that features Jane Doe and Joe Blow, both of whom are identified with an on-screen graphic but neither is identified in the audio track. This is a very simple (and common) need for description, which could be handled with a very simple WebVTT file:
WEBVTT 00:00:00.000 --> 00:00:05.000 Jane Doe 00:00:40.000 --> 00:00:45.000 Joe Blow
This description file could be synchronized with the video with code like this:
<video controls> <source src="video1.mp4" type="video/mp4"> <source src="video1.webm" type="video/webm"> <track kind="captions" src="video1_cap.vtt" srclang="en" label="English captions"> <track kind="subtitles" src="video1_es.vtt" srclang="es" label="Español"> <track kind="descriptions" src="video1_desc.vtt" srclang="en" label="Audio description (English)"> </video>
Note that this example includes three tracks: Captions in English, Subtitles in Spanish, and audio description in English.
The idea with delivering description as timed text is that the description text can be exposed at the specified times in sync with the video. It can then be read aloud by screen readers, or self-voiced by the browser or media player.
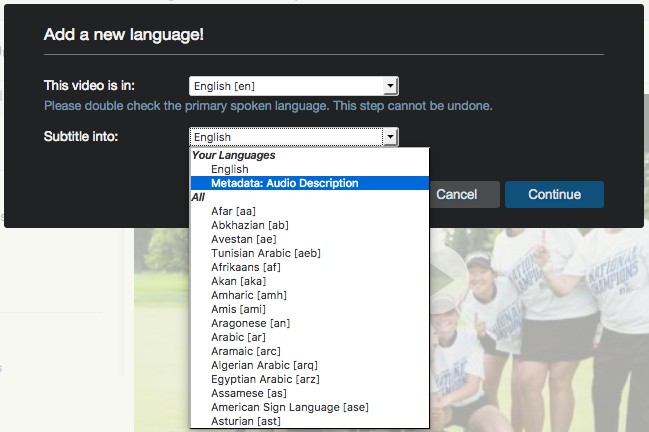
Creating timed text files is easy. A WebVTT file like the example above can be created in 30 seconds in any text editor. Alternatively, as long as the need for description is simple, any tool that’s used for editing captions can be repurposed for editing descriptions. Simply watch the video, and instead of typing what you hear, type succinct descriptions of any content that is otherwise only available visually (e.g., “Jane Doe”, “Joe Blow”). At least one captioning/subtitling tool, Amara.org, is aware of this use case for their tool and offers “Metadata: audio description” as one of the languages that videos can be translated into.
Also, the National Center on Accessible Media (NCAM) at WGBH in Boston, the people who brought us MAGpie, recently announced their new tool called CADET. The acronym stands for “Caption and Description Editing Tool”, which suggests their intent is for this editor to be used for creating and editing both captions and descriptions.
If choosing to do it yourself or tackle the problem with in-house staff, it’s important to respect the challenge of describing visual content. Unlike captioning, the words you choose can have an impact on the message. The Described and Captioned Media Program (DCMP) has developed a Description key that explicitly documents best practices. Anyone doing this work should be familiar with them. There also are many opportunities to receive audio description training.
Another positive development, hot off the press: Both 3PlayMedia and AutomaticSync, companies that historically have provided captioning services, have announced their intent to enter the audio description market. Both of these companies are capable of systematically delivering large quantities of timed text files. They’ve done it for many years with captions, and have developed dozens of integrations with products and services like YouTube, Brightcove, Echo360, Kaltura, Mediasite, Panopto, and many more. Their announcements, and the overall growing interest in text-based description, have me optimistic that this can be a key part of the solution we’ve been seeking.
For more information about the offerings of these companies, see their websites:
Automatic Sync doesn’t officially mention audio description yet on their website, but the page linked above includes ways to contact them to express interest or find out more.
Which methods are supported by media players?
Able Player, the free media player I developed with much-appreciated help from the open source community, supports both methods. Here are three different methods for adding audio description to video using Able Player:
- To add a described version of a video, add both a src and data-desc-src attribute to the <source> element, specifying the path to the non-described and described versions of the video respectively. The player controller includes an audio description button if descriptions are available. If the user has that button toggled on, they get the described version. Otherwise, they get the non-described version.
- For YouTube videos, add both a data-youtube-id and data-youtube-desc-id attribute to the <video> element. The value of these attributes is the YouTube ID of the non-described version and described version respectively. It’s easy enough to upload a described video to YouTube, but YouTube offers no way to explicitly associate the described and non-described versions. Able Player makes that possible. As in the previous method, the video that ultimately gets played depends on the state of the Audio Description button on the player controller.
- To add text-based description, simply use the <track> element with kind=”descriptions” as explained above. Able Player supports this by exposing description text in an ARIA live region so screen readers announce it as it appears. In cases where there isn’t enough time for description to be read before it conflicts with program audio, users can turn on an optional feature within Able Player’s preferences that automatically pauses the video whenever description starts.
As far as I know, the only other media players that support audio description in any way are Oz Player, JW Player, and VideoJS. Oz Player supports audio description via a separate audio file, toggled on/off via an AD button. JW Player, prior to version 6, also supported audio description as a separate audio file and required an “Audio Description” Plugin. This included a optional ducking feature that lowered program audio temporarily when description audio was playing. Starting with version 6, JW Player has changed its approach and now supports multiple audio tracks for a single video via HTTP Live Streaming. This can be used for a variety of purposes in addition to audio description (e.g., dubbed translations, directors cuts), but currently only works in IE11 & Safari. Other browsers require Flash. For more information see JW Player’s developer docs on HLSV4 Audio Tracks. VideoJS uses the same approach as JW Player, via the VideoJS Audio Tracks plugin, and has the same browser limitations.
3PlayMedia is responding to the lack of standard support for description among media players by providing a plugin that references the original video source and plays the secondary audio description track along with that. I haven’t seen this in action yet, but I’m looking forward to taking it for a spin. I suspect Automatic Sync will do something similar.
No single solution for all your video needs
I think both methods of delivering audio description are necessary for meeting the needs of higher education institutions. At the UW, I’ve sampled a lot of video over the last few months, and find that the videos we’ve produced tend to be distributed fairly evenly across the following five categories:
- Lectures. If lecturers are good at verbalizing visual details such as slide content or scribbles on the white board, no description is needed. However, if lecturers haven’t mastered these skills, their lectures may require some description. This could be a good use case for text-based description if the visual content isn’t too complex.
- Documentary-style videos. At the UW these are typically grant-funded videos that describe research projects and scientific or medical innovations. Generally all important information is available via the narration, and little or no additional description is required. The most common exception is when videos have multiple speakers, and the name and affiliation of each speaker is presented in an on-screen graphic but not stated audibly (as in the Jane Doe and Joe Blow example above). Adding the names and affiliations of speakers as description is relatively trivial, and is a perfect use case for text-based description.
- Tutorial videos. With advances in screen capture software, it’s increasingly easy to create videos showing how to perform a task on the computer. These videos typically include narration describing the steps, but often the narration lacks critical detail and is narrated with the assumption that viewers can see the screen and use the mouse (e.g., “First click here… now click here”). The ideal strategy for addressing accessibility of these videos is to educate the people creating them. Meanwhile, description may be required to fill in the gaps of missing information. Text-based description could be a good fit for these videos, and the person who created the video should be asked to write the description.
- Highly visual videos. There seems to be a trend in video-based marketing away from spoken audio; instead, ideas are presented with images and music alone (the Best of UW video is a perfect example). This technique is used to convey emotion, not just information, and it’s important that audio description do the same. These sorts of videos should probably be narrated by humans, and should be left to the professionals.
So, we have a variety of types of videos, and therefore need a variety of solutions for describing them, utilizing both Method One and Method Two. One challenge is getting video owners throughout the institution to understand which method is appropriate for a given video. As with all things related to accessibility, this will require a massive effort to educate our campus community.
Have others taken steps to address audio description needs within your organization? If so, please share via the comments.
2 replies on “My Audio Description Talk @ CSUN”
[…] My Audio Description Talk @ CSUN by Terrill Thompson […]
[…] cost of description differs greatly from provider to provider, and even from video to video. This is because the need for description […]