Today I’m celebrating Independence Day by declaring independence from presentational HTML markup!
In my previous blog post I explored strategies for converting Microsoft Word docs to accessible PDF and HTML. For HTML, I found that Word produces a relatively clean HTML file if you save to “Web page, filtered” in Word 2010 or 2013 for Windows or “Save only display information into HTML” in Word 2011 for Mac.
The HTML that Word produces preserves heading structure, includes image Title and Description together as a combined alt attribute, preserves language of the document and any foreign language parts, and preserves table headers.
However, there are two problems with Word’s output:
- Lists are tagged as paragraphs.
- There is no way to suppress style output; consequently the document contains embedded CSS plus width, align, and other presentational attributes that are designed to preserve the visual appearance of the document.
Regarding the latter problem, I don’t want any presentational markup in my document! I plan to plug the content into a website that already has an external style sheet. I want complete separation of content and structure from presentation.
I tried several online Word to HTML converters without satisfaction. Even HTML Tidy (e.g., HTML Tidy Online) doesn’t seem to have an option to achieve my desired level of tidiness. The only solution I’ve found is to manually strip out all the unwanted markup using an HTML editor. This sounds tedious but most HTML editors include an option that allows users to search and replace content using regular expressions, which greatly streamlines the process.
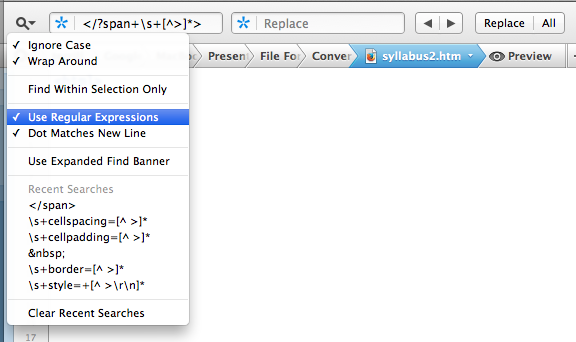
Search/Replace with Regular Expressions
Regular expressions are strings of characters that are used in pattern matching. They’re entirely unreadable for people who don’t know the language, and I’ve always considered them to be the domain of Hard Core Geeks. I don’t profess to be an expert, but I’m fascinated by their efficiency and for nostalgic reasons I enjoy using code that originated in the early days of computing.
Following are the regular expressions I use to clean up Word’s filtered, but not quite filtered enough, HTML files. I just find all text that matches each expression, and replace it with nothing.
- \s+class=[^ >]*
- Finds any class attributes and the white space that precedes it, regardless of whether the value of the attribute is enclosed in quotes.
- \s+align=[^ >]*
- Same as above, but finds align attributes.
- \s+width=[^ >]*
- Same as above, but finds width attributes.
- \s+valign=[^ >]*
- Same as above, but finds valign attributes.
- \s+style=’+[^’]*’
- Finds all inline style attributes, even those that include spaces and line breaks, providing their values are always enclosed in single quotes, which they seem to be.
- \s+style=”+[^”]*”
- Same as above, but detects styles that are enclosed in double quotes. The first version works in HTML created by Word; this second version works in HTML created by Libre Office (see below for more on Libre Office)
- </?span+\s+[^>]*>
- Finds all <span> elements, including any attributes.
- </span>
- Finds all closing </span> tags.
-
- Finds all encoded spaces. These are, 99% of the time, unnecessary.
- <p></p>
- Finds all empty paragraphs.
If a document includes data tables, a few additional searches are required:
- \s+border=[^ >]*
- Finds any border attribute and the white space that precedes it, regardless of whether the value of the attribute is enclosed in quotes.
- \s+cellpadding=[^ >]*
- Same as above, but finds cellpadding attributes.
- \s+cellspacing=[^ >]*
- Same as above, but finds cellspacing attributes.
Of course, this results in a relatively clean table, but not a fully accessible one. Now you have to add the necessary markup to make it accessible. WebAIM explains this well in their Creating Accessible Tables tutorial.
Putting it all together
One could perform one massive find and replace operation by stringing all of the above expressions together, separated by the OR operator (“|”), like so:
Word Version
Libre Office Version
Only a Start
I suspect this is only skimming the surface of the problem as it’s based entirely on my experience with fairly simple Word documents. But it’s a start. I welcome suggestions.
Dealing with Word’s Listless Lists
The above expressions do not address the problem of Word exporting lists to HTML paragraphs. I created a List Test in Word and exported that to a List Test in HTML. In studying the latter, here’s what I think I know about Word’s list code:
- Each list item is coded as a paragraph and has a class attribute. In my sample, the class is “MsoListParagraph”, but that’s not reliable. It’s tied to the style folks are applying to their list in Word, and could be anything.
- Each paragraph also has a style attribute.
- Inside each paragraph is a <span> tag followed by one or more characters that represent the symbol or number. There’s some guessing involved here, but if the symbol includes a number 1-9, letter “a” through “n” in upper or lower case, then this is an ordered list. Otherwise it’s an unordered list. (Lists must stop at the letter “n” because the letter “o” is used as one of the bullet symbols.
- This symbol is followed by another <span> tag that contains one or more characters, and all this ends with two closing </span> tags.
Matching the above pattern and replacing it all with a <li> would seem to be fairly straightforward using regular expressions, but I’m stumped on how to figure out where a list begins and ends, which is necessary so we know where to place the opening and closing <ul> or <ol> tags.
Any Hard Core Geeks in the crowd who are up to the challenge of figuring that out?
Use Libre Office
In my previous blog post, I found that Libre Office does a better job than Word at exporting to both PDF and HTML. Its HTML output includes gobs of presentational markup just like Word’s output does, but at least it exports lists as lists (albeit without closing </li> tags).
So, one seemingly complete solution for exporting from Word to HTML would be to follow these steps:
- Open the Word doc in Libre Office.
- Save As > HTML Document.
- Open the HTML document in an HTML editor then find and replace unwanted presentational code using the above regular expressions.
- Run the final output through HTML Tidy to cleanup any lingering problems (e.g., add closing </li> tags).
One problem with Libre Office is that it doesn’t include header tags in its data tables, but data tables will require additional editing anyway to be made fully accessible, so that really isn’t a problem.
Now, time for BBQ and fireworks…
One reply on “Cleaning up Word’s HTML with Regular Expressions”
Seems like a good solution might be loading the HTML into Casperjs and then manipulating the DOM, followed by exporting the DOM to a file. Should be more reliable than regex, I think. Maybe an open source project?